original post: http://blog.stackstate.com/the-monitoring-maturity-model-explained
The pace of change is increasing. Component sizes are shrinking. All the while monitoring solutions are bombarding us with log data, metrics, status reports and alerts. It all scales, but we don’t. How do we prevent from drowning in run-time data?
变化的速度原来越快,组件越来越小,与此同时监控解决方案中log data,metrics,status,report还有alters这些东西也一直轰炸我们,他们的规模都在上涨,而我们却没有,我们如何避免被淹没在这些数据中?
A lot of companies are facing the same problem. They have such a huge amount of data, but can’t get a total unified overview. When problems occur in their IT stack, they don’t know where it originates. Was it a change, an overload, an attack or something else? Based on our experience, we created the Monitoring Maturity Model. At which level is your company now?
很多公司都面临同一个问题,他们都有这么多数据,但是无法得到一个完整的概览,当一个问题出现在他们的it环境中,他们不知道哪里是出问题的源头,到底是一次变更,还是负载过高,或者是一次攻击还是其他事情引起的这次故障?根据我们的经验,我们做了一个监控成熟度的模型的评估表,看看你的公司现在处于什么级别?
Level 1 - Health of your components
At level one you have different components, but monitor solutions at this level only report if they are up or down. If something happens in your IT stack, you will see a lot of red dots and you will probably get a lot of e-mails which say there is something broken. So at level one you will only see the states and alert notifications per (single) component.
level 1 - 每个被监控组件的健康状态
在1 这个级别,你有不同的被组件,但是你的监控方案只能做到报告这些组件的状态是up 或 down,如果这时候在你的it系统中有一些故障发生,你会看到很多红点警告,还有可能收到很多email,这些email告诉你有些东西坏了.所以在1这个级别你只能看到每个被监控组件的状态,和收到每个被监控组件的报警提醒.
Level 2 - In-depth monitoring on different levels
Most of the companies we’ve seen are at level two of the Monitoring Maturity Model. At this level you are monitoring on different levels and from different angles and sources. Tools like Splunk or Kibana are used for log files analysis. Appdynamics or New Relic are used for Application Performance Monitoring. Finally we have tools like Opsview to see the component’s states of different services. And that’s a good thing, because you need all this kind of data. The more data you have, the more insight you have on the different components. So at this level you are able to get more in-depth insight on the systems your own team is using.
But what if something fails somewhere deep down in your IT stack, which affects your team? Any change or minor failure in your IT landscape can create a domino effect and eventually stop the delivery of core business functions. Your team only sees their part of the total stack. For this problem, we introduce level three of the Monitoring Maturity Model.
级别2 - 不同级别的深入监控
我们见到的大多数公司在监控成熟度模型中都处于2级 这个级别,在这个级别,你会从不同的级别和不同的角度还有不同源头分别做监控,像splunk,kibana这些都用来做日志文件分析, Appdynamics 或者New Relic 这些工具用来做应用的性能监控,最后我们会有类似opsview这种工具来看每个被监控组件的不同的服务的状态.这些都是很好的功能,因为你需要所有的这些类型的数据,你数据越多,你会对不同被监控组件的了解越深.所以在这个级别,你会对你的系统有更多的深入了解.
但是,当一个问题发生在你it系统的特别难发现的地方时候,是否会影响到你的team?任何一个变更或一个小的问题在你的整个it系统中可能会造成一种多米诺骨牌效应,最终影响到你核型业务.你的team只能看到整个架构中属于你们的那一部分.对于这个问题,我们就可以介绍一下级别3了.
Monitoring Maturity Model
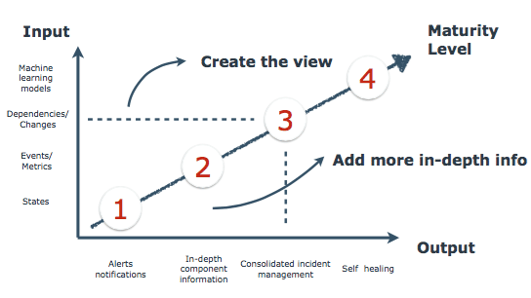
Level 3 - Create a total overview
At level three we don’t only look at all the states, events and metrics but also look at the dependencies and changes. Therefore you need an overview of your whole IT stack, which will be created using existing data from your available tools. To create this overview you will need data from tools like:
Monitoring tools (AppDynamics, New Relic, Splunk, Graylog2)
IT Management tools (Puppet, Jenkins, ServiceNow, XL-Deploy)
Incident Management tools (Jira, Pagerduty, Topdesk)
Re-use this existing data from different tools to create the total overview of your whole IT stack. At level three you are able to upgrade your entire organization. Now each team can view their team stack as part of the whole IT stack. So teams have a much easier job finding the cause of a failure. Also teams are now able to find each other when this is needed the most. This level also helps the company to get a unified overview while letting teams decide which tools they want/need to use.
级别3 - 做一个完整的概览
在级别3这个阶段,我们不不仅要看所有的stats,event,metrics,而且还要看每个被监控对象的依赖对象以及每个东西的变更.所以你需要有一个利用你现在所有数据和工具做出来的整个架构的概览.要做这个概览你需要类似这些类型的数据和工具
- 监控工具(ppDynamics, New Relic, Splunk, Graylog2)
- it 管理工具(Puppet, Jenkins, ServiceNow, XL-Deploy)
- 事件管理工具(Jira, Pagerduty, Topdesk)
重用这些以有工具生成的已有数据去生存一个整个系统的完整概览.在级别3,你能升级你的整个组织结构了.现在每个team能以全局的视角看到每个team自己的那一部分.现在这些team能在出问题的时候更容易找到问题发生的原因.而且现在这些team也可以在需要的时候找别的team.让每个team决定他们自己自己需要用活着想用的工具能帮助公司得到一个完整统一的系统概览.
Level 4 - Automated operations
Level four is part of our bigger vision, at this level we will be able to:
Send alerts before there is a failure
Self-heal by for example scaling up or rerouting services before a service is overloaded
Abnormality detection
Advanced signal processing
级别4 - 自动化操作
级别4是我们大前景的的一部分,在这个级别,我们可以:
在发生故障之前发送报警
自动修复,在负载过高的时候,自动扩展或者动态重新路由.
异常行为检测
高级信号处理